
The Transformer Architecture: The Foundation of Modern Large Language Models
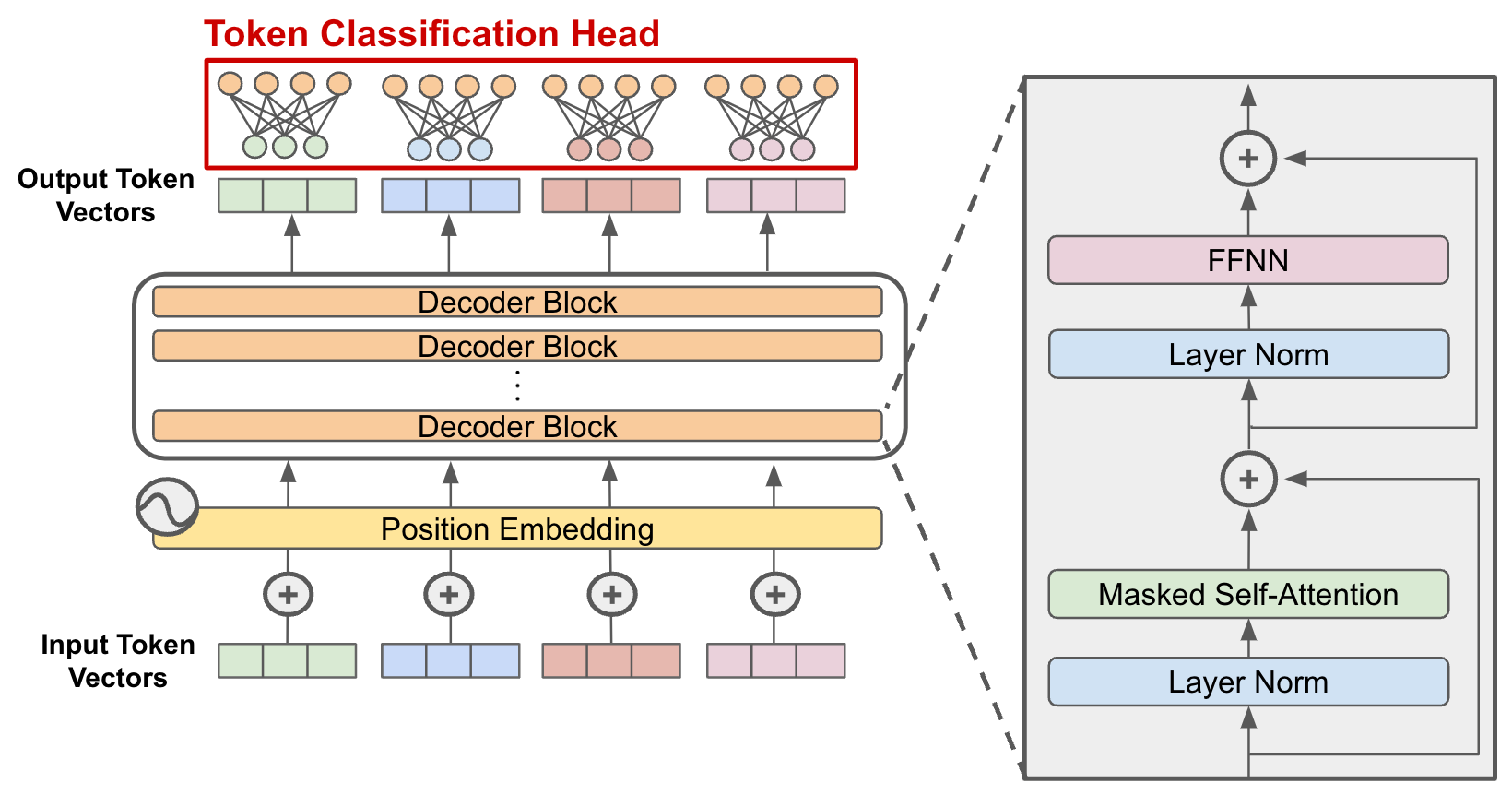
Imagine trying to read an entire book while only seeing one word at a time. That’s how older models in natural language processing operated—processing sequences step by step, often forgetting what came before. Transformers, however, revolutionised the scene by giving models the ability to read entire chapters at once, remembering context and relationships far better. This architectural breakthrough has become the backbone of today’s large language models, enabling them to generate text, translate languages, and answer complex questions with human-like fluency.
Breaking Free from Sequential Chains
Traditional recurrent models, like RNNs, could be compared to people standing in a long queue, passing messages one by one. By the time the message reached the end, much of its meaning was lost. Transformers eliminated this bottleneck through attention mechanisms—a method of letting the model focus on the most relevant words regardless of their position in the sentence.
This shift was like replacing a whispering game with a conference table discussion, where everyone can hear and weigh in simultaneously. Learners often first explore this concept in a data science course in Pune, where attention-based architectures are introduced as a milestone in the evolution of deep learning.
The Power of Attention
At the core of the Transformer lies the concept of self-attention. Instead of processing information in order, self-attention assigns weights to relationships between words, enabling models to capture nuance, context, and dependencies across long passages.
Think of it like a teacher marking the most critical sentences in a textbook with a highlighter. The highlighted content draws more attention, making it easier to understand the overall meaning. In a neural network, self-attention highlights relationships, ensuring that no detail is overlooked in the flood of data.
For those enrolled in a data scientist course, studying attention mechanisms offers a hands-on way to see how contextual understanding emerges—why a model knows that “bank” refers to money in one sentence and a river’s edge in another.
Stacking Layers Like Building Blocks
Transformers aren’t just about attention—they’re about scale. Multiple encoder and decoder layers, each equipped with attention heads, are stacked like building blocks. Each layer refines the information passed on to the next, much like drafts of an essay becoming sharper with every revision.
This stacking allows large language models to process enormous datasets and generate sophisticated outputs. The elegance of the architecture lies in its repeatability—simple blocks combined to achieve complexity.
When learners engage in practical projects during a data scientist course in Pune, they often experiment with smaller versions of Transformers before appreciating the sheer power of models like GPT or BERT. This gradual scaling teaches the principle that big breakthroughs come from simple ideas applied consistently at scale.
Applications Beyond Text
While Transformers gained fame in natural language processing, their reach extends beyond words. They now power computer vision, protein folding research, and even recommendation systems. By treating sequences of pixels, amino acids, or user interactions as “tokens,” the architecture adapts seamlessly to new domains.
It’s like inventing a tool for cutting wood that later proves equally effective for metal, stone, and fabric. This adaptability explains why Transformers dominate AI research today.
Students in a data scientist course often explore these cross-domain applications, learning how one architecture can unify seemingly unrelated fields. The versatility of Transformers demonstrates the importance of mastering core concepts deeply, as they often resurface in surprising ways.
The Future of AI Built on Transformers
The Transformer didn’t just improve performance—it redefined the possibilities of AI. Its ability to scale, adapt, and understand context continues to push boundaries in language, science, and industry. From chatbots to scientific discovery, the architecture has become the trusted compass guiding innovation.
Conclusion
The Transformer architecture stands as a turning point in artificial intelligence, shifting from sequential memory loss to holistic understanding. By focusing on attention, scaling through layers, and expanding across domains, it has built the foundation for today’s most advanced large language models.
For professionals, mastering these ideas is more than academic—it’s preparation for a future defined by intelligent systems. Just as the Transformer reshaped AI, understanding its principles can reshape careers in data and machine learning.
Business Name: ExcelR – Data Science, Data Analytics Course Training in Pune
Address: 101 A ,1st Floor, Siddh Icon, Baner Rd, opposite Lane To Royal Enfield Showroom, beside Asian Box Restaurant, Baner, Pune, Maharashtra 411045
Phone Number: 098809 13504
Email Id: enquiry@excelr.com